Pełny przegląd 14 sekcji audytu widoczności marki w modelach AI. Każdy raport AIScan to ~40-stronicowy PDF z liczbami, źródłami, fragmentami stron, śladem decyzyjnym AI i wizualizacjami, plus osobny Załącznik C — `responses.html` z pełnym zapisem 184 odpowiedzi AI (timestamp + dokładny model AI per odpowiedź — pełna replikowalność). Poniżej rzeczywisty audyt firmy bikeworkshop.pl (serwis rowerowy w Bielsku-Białej, pierwsza linia działalności właściciela AIScan, publikowany za zgodą jako case study). Konkurenci anonimizowani jako Konkurent A–G (liczby, ranking i fragmenty cytowane są autentyczne, tylko nazwy zastąpione).
Klient końcowy coraz częściej zadaje pytania zakupowe nie Google, lecz ChatGPT, Claude lub Gemini. Wynik wyszukiwania to nie 10 niebieskich linków, lecz wygenerowana odpowiedź — model AI sam wybiera, które marki wymieni, w jakiej kolejności, z jakich źródeł zaczerpnie informacje. Tradycyjne SEO mierzy widoczność w wynikach Google. GEO (Generative Engine Optimization) mierzy widoczność w odpowiedziach modeli AI.
Audyt AIScan to 184 kontrolowanych zapytań do trzech modeli AI (Anthropic Claude, OpenAI GPT, Google Gemini) w dwóch trybach pracy (z wyszukiwaniem webowym i bez) — symulacja typowych pytań klienta z branży. Każda odpowiedź jest analizowana pod kątem: które marki wymieniono, w jakiej kolejności, z jakich źródeł AI zaczerpnął informacje, jakie zapytania wygenerował w tle, jakich danych zabrakło. Plus drugi model AI (Claude Haiku) klasyfikuje każdą wzmiankę jako rekomendację, neutralną wzmiankę albo brak. Wynik to faktograficzny raport — pomiar stanu, nie rekomendacje marketingowe.
AIScan jest niezależnym audytem — nie świadczymy usług optymalizacyjnych (SEO, content marketing, GEO). Zero konfliktu interesów. Raport jest danymi, nie sprzedażą drugiej usługi.
Spis 14 sekcji raportu
Każda sekcja raportu to inna warstwa pomiaru widoczności marki w AI. Kliknij, by zobaczyć szczegółowy opis i zrzut z prawdziwego audytu:
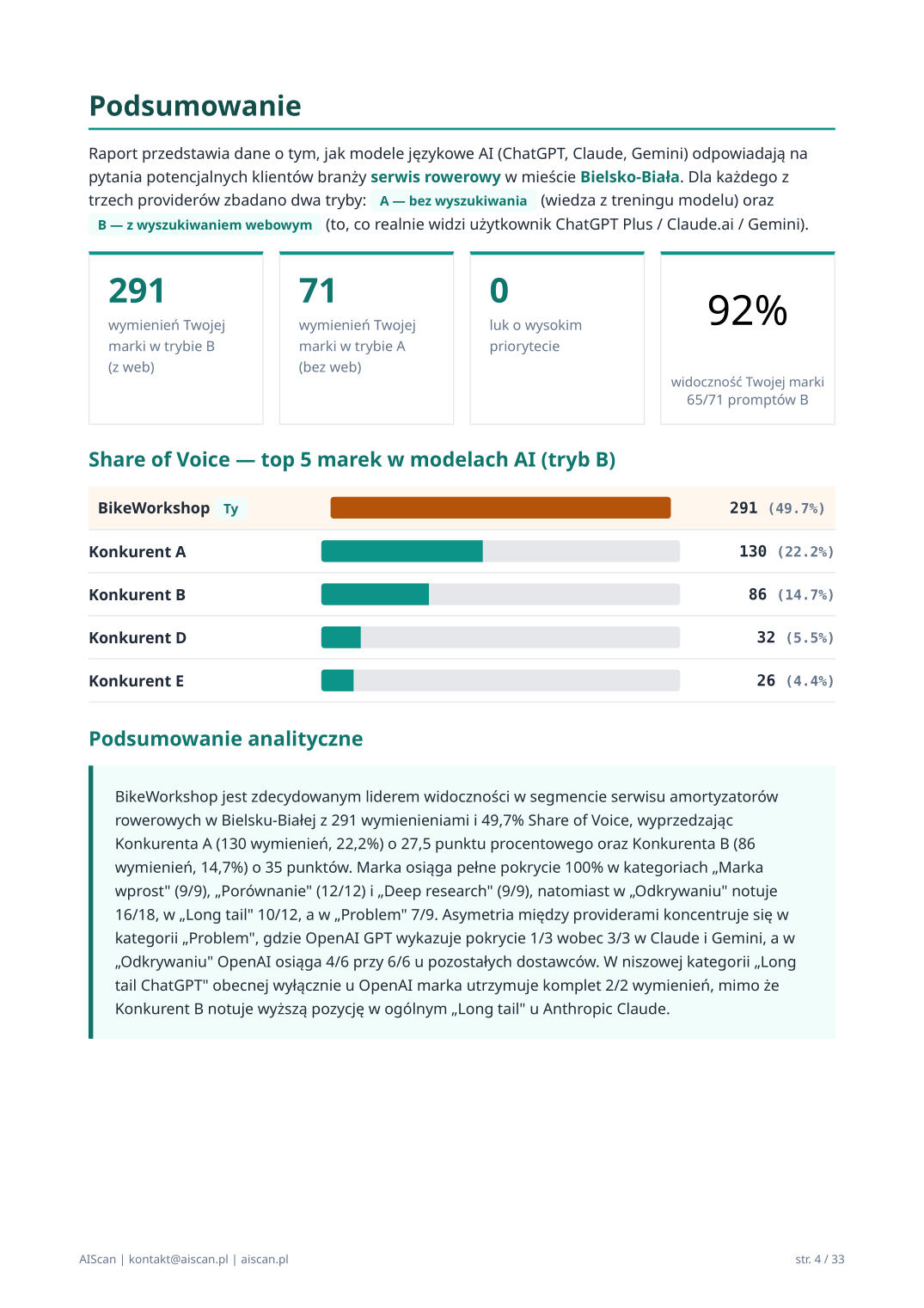
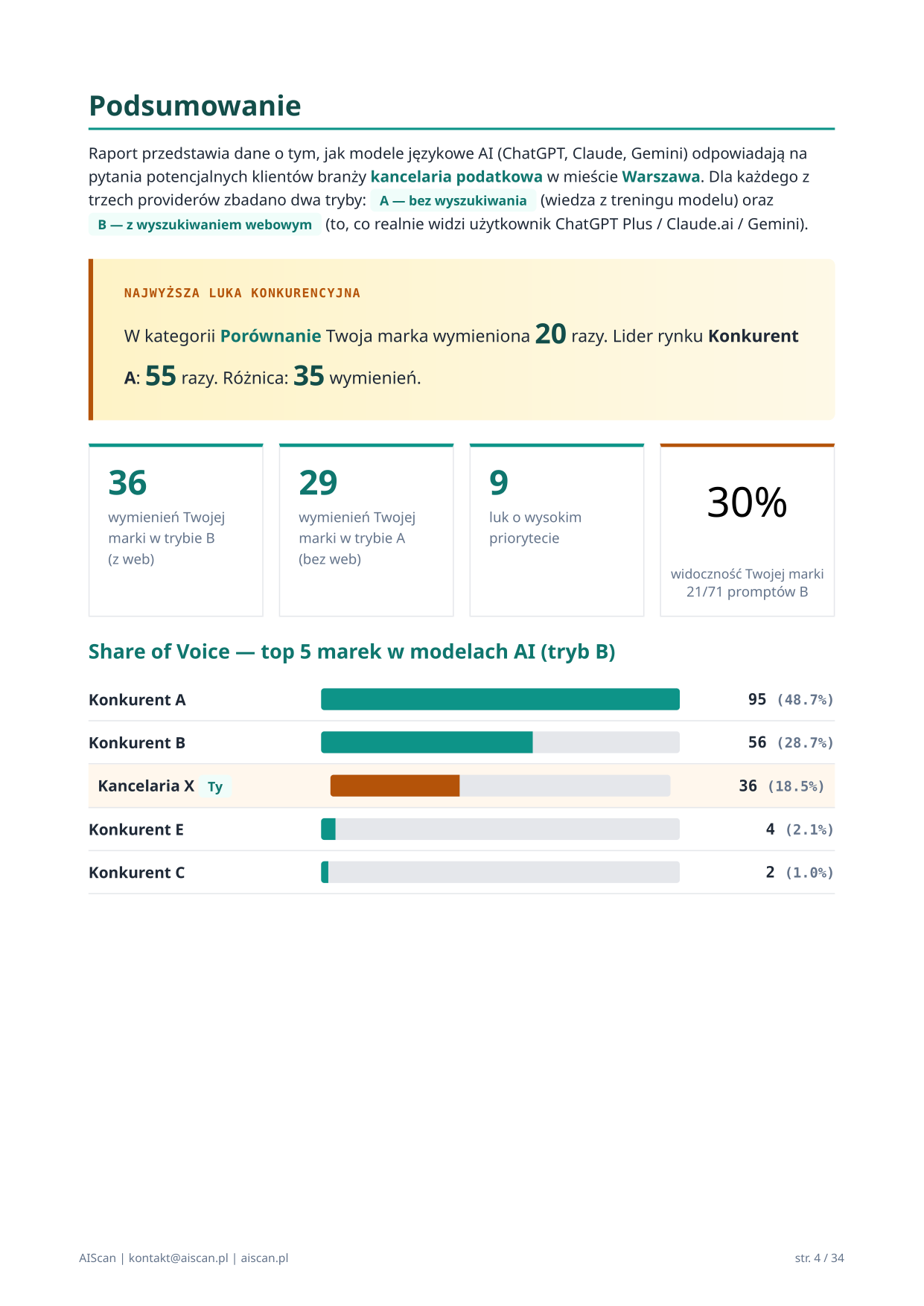
Podsumowanie — Organic SOV donut, Total SOV, Brand recall, narracja Opus
Pierwsza sekcja merytoryczna raportu — wszystko, co decyzyjny czytelnik (CEO, dyrektor marketingu) potrzebuje wiedzieć w 30 sekund. Składa się z czterech elementów:
Donut SVG „Organic SOV" — kluczowa metryka raportu. Procentowy udział marki klienta w odpowiedziach AI w trybie B z wykluczeniem kategorii „Marka wprost" i „Porównanie" (tam klient jest w pytaniu, więc gwarantowany w odpowiedzi — sztuczny szum). Kolor severity: zielony (>30%), bursztynowy (10–30%), czerwony (<10%).
Subtitle Total SOV pod donutem — pokazuje pełny udział z wszystkimi kategoriami, jako referencja dla porównania (Total > Organic = miarą inflation z brand_direct).
Card Brand recall — udział w kategorii „Marka wprost" (gdy AI dostaje nazwę firmy w pytaniu). Mierzy jak silnie AI zna markę przy bezpośrednim odpytaniu.
Card luki — liczba kategorii zapytań z 0 wymienień klienta (priorytet wysoki).
Organic SOV bar chart — top 5 marek w organicznym discovery, klient wyróżniony pomarańczowym.
Podsumowanie analityczne — 4-zdaniowa narracja generowana przez Claude Opus 4.7 (flagship Anthropic) na podstawie liczb audytu. Faktograficzna proza B2B, zero rekomendacji.
W audycie BikeWorkshop sekcja pokazuje: donut 35,1% Organic SOV (bursztynowy, lider organicznego discovery), Total SOV 49,7%, Brand recall 100%, liczby konkurentów (Konkurent B 23,4% Organic, Konkurent A 20,4% Organic) i Opus prose:
„BikeWorkshop jest liderem organicznego discovery z 129 wymienieniami i 35,1% Organic SOV, wyprzedzając Konkurenta B (86 wymienień, 23,4%) o 11,7 punktu procentowego oraz Konkurenta A (75 wymienień, 20,4%) o 14,7 punktu. Pełen Total SOV (49,7%) jest sztucznie zawyżony przez kategorię „Marka wprost" gdzie marka pojawia się 100% — Organic SOV pokazuje realną pozycję w spontanicznym discovery klienta końcowego. Marka osiąga pełne Brand recall (100% w „Marka wprost") oraz pełne pokrycie w „Porównaniu" i „Deep research", natomiast w „Odkrywaniu" notuje 16/18. Asymetria między providerami uwidacznia się w kategorii „Problem", gdzie OpenAI GPT pokrywa 1/3 zapytań wobec 3/3 u Claude i Gemini."
Strona „Podsumowanie" raportu (str. 4 PDF)
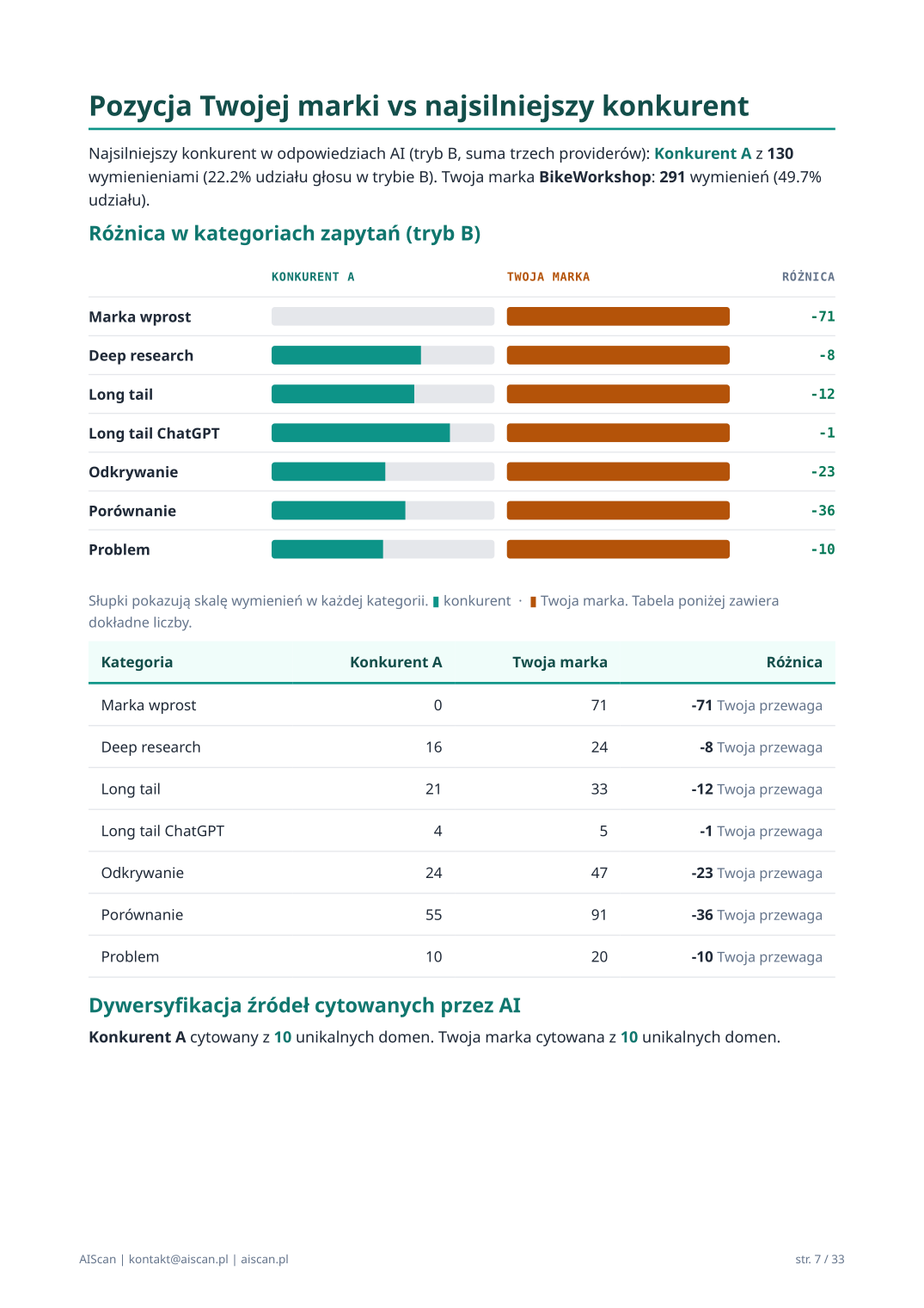
02 · Pozycja Twojej marki vs najsilniejszy konkurent
Head-to-head między marką klienta a top konkurentem (drugą najczęściej wymienianą marką w trybie B). Pokazuje konkretny pojedynek: kategoria po kategorii — kto wygrywa, ile wynosi luka, ile unikalnych domen cytuje AI dla każdej z marek.
Kluczowy element wizualny to compare bars — równolegle 2 słupki na każdą kategorię intencji (audytowana marka pomarańczowa, konkurent teal). Widać w sekundzie, gdzie jest dominacja, gdzie luka.
Druga część sekcji to dywersyfikacja źródeł: ile unikalnych domen cytuje AI dla audytowanej marki vs konkurenta, top 5 domen po obu stronach. Pokazuje, czy marka żyje w ekosystemie AI z 1 domeny (własnej strony) czy z 5+ (recenzje, katalogi, media).
Strona „Pozycja Twojej marki vs najsilniejszy konkurent" (str. 7 PDF)
03 · Obserwacje i kierunki
Najważniejsza analitycznie sekcja raportu — zagregowane wzorce semantyczne, nie atomowe powtórki per provider. Maksymalnie 7 obserwacji, każda w formacie 6-polowym (wzorzec Gartner/Forrester):
Tytuł — krótki nagłówek, identyfikuje wzorzec.
Stan faktyczny — co konkretnie zmierzono, z liczbami.
Wzorzec w danych — kontekst, porównanie z konkurencją w tej samej kategorii.
Mechanizm działania AI — dlaczego AI tak odpowiada (definicja jak AI działa w danej kategorii).
Możliwe kierunki — neutralne wskazania obszarów do rozważenia (zawsze opcje, nigdy „rób to").
Weryfikacja — jak ponowny audyt za 90 dni pokaże zmianę.
Cztery wzorce automatycznie wykrywane:
Universal blind spot — 0 wymienień klienta we wszystkich 3 modelach w danej kategorii (priorytet wysoki dla Odkrywanie / Problem / Deep research).
Asymmetria binarna — ≥1 model widzi, ≥1 nie widzi (priorytet średni).
Asymmetria skalowa — wszyscy widzą, ale jeden provider ≥2× rzadziej (priorytet średni dla high cats, niski dla medium).
Konkurent przebijający w (Provider × Category × Tryb) — wartościowe nawet gdy klient jest globalnym liderem (np. lider 35,1% Organic SOV ale w niszowej Long tail u Claude konkurent X dominuje).
Forma informacyjna, nigdy doradcza: „Marka X niewidoczna w 0/9 promptach kategorii Problem we wszystkich 3 modelach AI" — bez „rekomendujemy", „powinieneś", „warto". Zgodnie z pozycją niezależnego audytora.
04 · Ślad decyzyjny AI
Najgłębsza warstwa pomiaru — pełny rozkład 8 najinformatywniejszych decyzji modelu AI (heurystyka pre-filtruje top 8 z 60–80 odpowiedzi trybu B per audyt, na podstawie sygnałów luki klienta).
Każdy ślad decyzyjny zawiera:
Prompt klienta — oryginalne polskie zapytanie z kategorii i providera.
Search queries wygenerowane przez model w tle do wyszukiwarki — pokazuje, jak AI „tłumaczy" prompt na zapytania.
Top źródła cytowane — domeny + URL fragmentów, z których AI zbudował odpowiedź.
Kolejność wymienienia marek — która marka pojawiła się jako #1, #2, #3 w odpowiedzi (pozycja często ważniejsza niż liczba wymienień).
Brakujące dane — lista konkretnych faktów, których AI nie znalazł i które ograniczyły kompletność odpowiedzi.
To killer feature raportu. Widać konkretne ślady — np. trace #3: „Konkurent A wymieniony jako #1 z sygnałami: opinie, kontakt, rezerwacja_online, lokalizacja. Audytowana marka nieobecna w odpowiedzi. Brakujące dane: aktualny cennik, godziny otwarcia, numer telefonu". To jest empiryczna diagnoza w pojedynczej decyzji modelu, nie agregat.
Pojedynczy ślad decyzyjny z sekcji „Ślad decyzyjny AI" (str. 13 PDF)
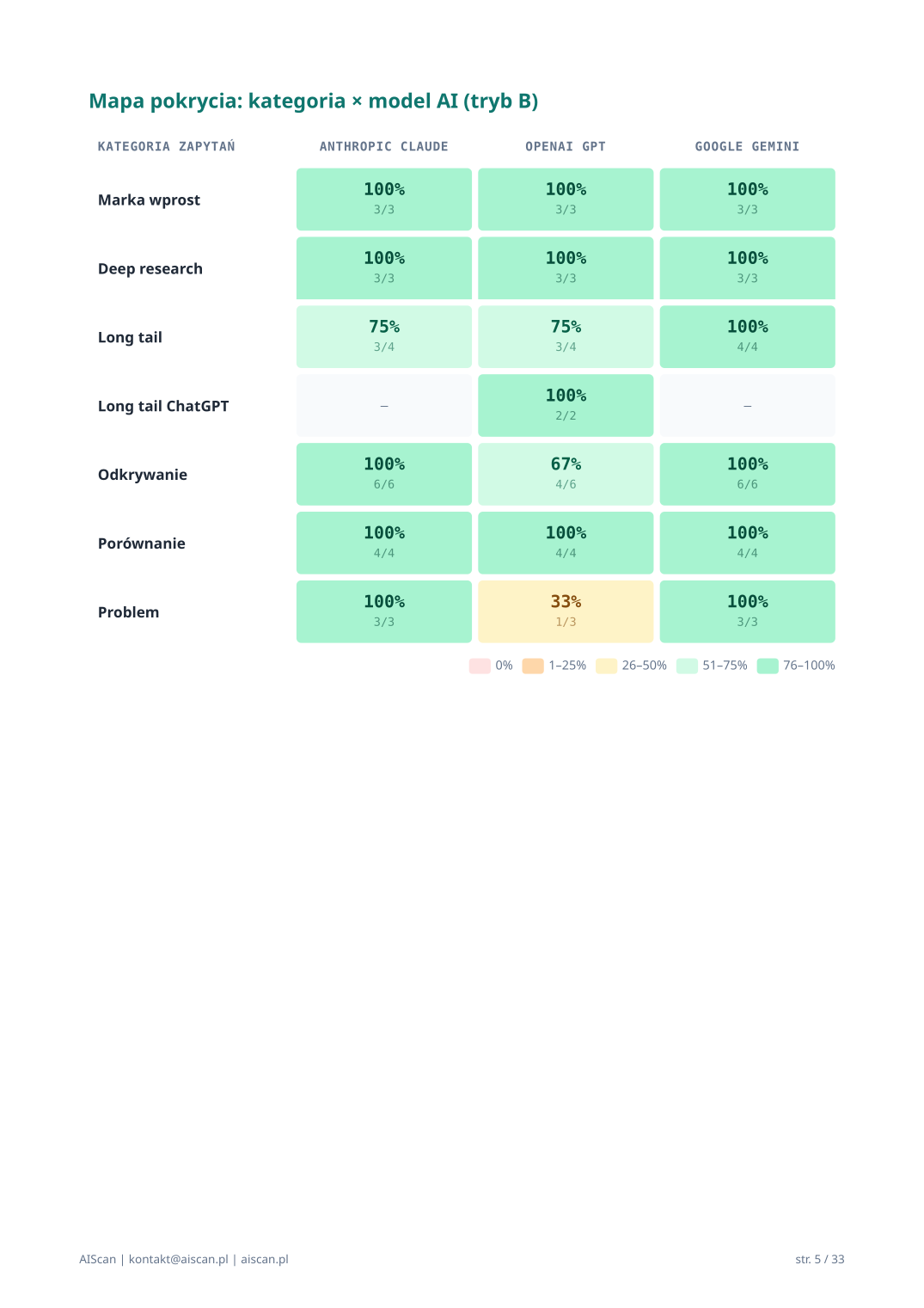
05 · Mapa pokrycia (kategoria × model AI)
Wizualna mapa stanu widoczności klienta w 3 modelach AI × 6+ kategoriach intencji jednocześnie. Heatmap CSS-only z gradientem cool→warm (5 kubełków):
🔴 0% — alarm, brak widoczności
🟠 1–25% — luka znacząca
🟡 26–50% — luka umiarkowana
🟢 51–75% — pokrycie dobre
🟢 76–100% — pełne pokrycie
Widać w sekundzie cały obraz: które kategorie mają zielono u wszystkich providerów, które mają czerwone luki, gdzie asymmetria. W audycie BikeWorkshop heatmap pokazuje 8 kategorii × 3 providery = ~22 komórki (long_tail_chatgpt tylko OpenAI, long_tail_budget opcjonalna). Większość zielonych (lider rynku), ale jeden wyróżniający się czerwony — OpenAI GPT „Problem" 33% — natychmiastowy sygnał gdzie kierować uwagę.
Strona „Mapa pokrycia" — heatmap kategoria × model AI (str. 5 PDF)
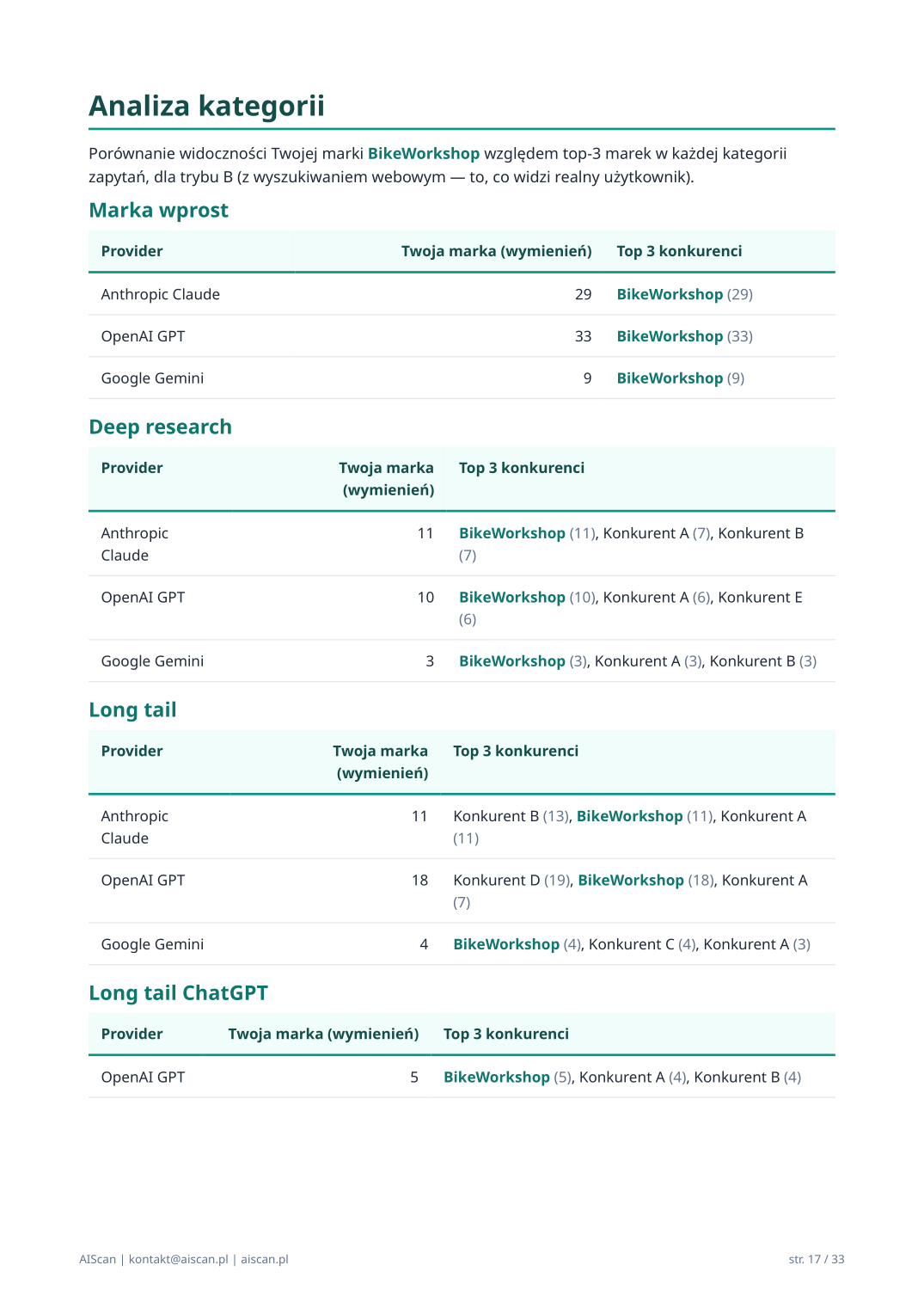
06 · Analiza kategorii
Per kategoria intencji (Odkrywanie / Porównanie / Problem / Deep research / Marka wprost / Long tail / Long tail ChatGPT) — top 3 marki wymienione w odpowiedziach AI, z liczbami per provider i trybem B.
Pokazuje strukturę rynku w danej kategorii — kto jest dominantem w „Odkrywaniu" (zwykle inny niż w „Deep research"), kto wygrywa „Porównaniach", w której kategorii audytowana marka ma realny rozkład udziałów. Format tabularny — łatwy do skanowania, łatwy do cytowania w prezentacji.
Sekcja warunkowa — wyświetla tylko kategorie, w których jakiś provider miał ≥1 prompt (np. „Long tail ChatGPT" pokaże się tylko jeśli odpalono casual ChatGPT-style prompty).
07 · Dominanci rynku AI
Pełen ranking marek w trybie B (suma 3 providerów) — top 8 marek, ich liczby wymienień, procent SOV, czy audytowana marka jest na liście (highlight). Daje pełen obraz „gdzie jestem w rankingu rynku, kto stoi przede mną, kto za mną".
Liczby agregują wszystkie 3 modele AI — to jest zagregowana widoczność rynku, niezależnie od tego, którego modelu używa odbiorca końcowy. Ważna metryka strategiczna: nawet jeśli marka jest cytowana 3-4× rzadziej u OpenAI niż Claude, w globalnej widoczności liczy się suma.
08 · Ekosystem źródeł cytowanych przez AI
Top 12 domen, z których AI brał informacje przy odpowiadaniu na 184 zapytania audytu. Pokazuje krajobraz autorytetów w niszy audytowanej marki:
Lokalne katalogi i agregatory opinii — Trustpilot, Cylex, ZnaneFirmy, ZłotaFirma
Branżowe media i autorytety — strony producentów, niezależnych serwisów, blogów eksperckich
Domeny śledzonych marek — własna strona audytowanej marki + strony konkurentów
Druga tabela: domeny cytowane w odpowiedziach z każdą marką — top 5 domen per marka. Widać, czy autorytet konkurencji jest budowany na własnej stronie (.pl konkurenta), czy na ekosystemie zewnętrznym (Facebook, ZnaneFirmy, Wikipedia, agregatory).
Strona „Ekosystem źródeł cytowanych przez AI" (str. 17 PDF)
09 · Co AI czyta na stronach konkurencji
Literalne fragmenty cited_text z Anthropic Claude (jedyny provider zwracający pełne 50–300-znakowe fragmenty stron). Pokazuje, którą część strony konkurenta AI uznał za autorytatywną odpowiedź na pytanie klienta.
To wartościowy research competitive — widać konkretny copy konkurencji, który „działa" w AI. Często to nieoczywiste fragmenty: opisy procesów, FAQ, sekcje cennikowe, opinie cytowane na stronie. Daje empiryczny benchmark, jakie treści są konsumowane przez AI.
Per marka pokazane są 2 najważniejsze fragmenty (z różnych URL-i, deduplikowane). Sekcja pokazuje konkretną treść, która buduje pozycję każdej marki.
10 · Jak modele AI tłumaczą polskie zapytania
Model AI w trybie B nie wysyła do wyszukiwarki literalnego promptu klienta — generuje własne search queries, „tłumaczące" intencję na frazy wyszukiwania. Sekcja pokazuje 6 reprezentatywnych próbek (po 2 per provider) z kategorii dyskrecjonarnych (Odkrywanie / Problem / Deep research).
Wartość biznesowa: sekcja pokazuje, jakie frazy AI faktycznie wyszukuje — często rozszerzone, dodające synonimy, lokalizację, atrybuty jakościowe. Te frazy to realne queries do których warto być widocznym w SEO — bo AI je wyszukuje przed sformułowaniem odpowiedzi.
Przykładowe queries wygenerowane przez OpenAI GPT z polskiego promptu „Gdzie zrobić serwis amortyzatorów rowerowych w Bielsku-Białej?":
Wrocław stomatologia estetyczna Google Maps najlepiej oceniane
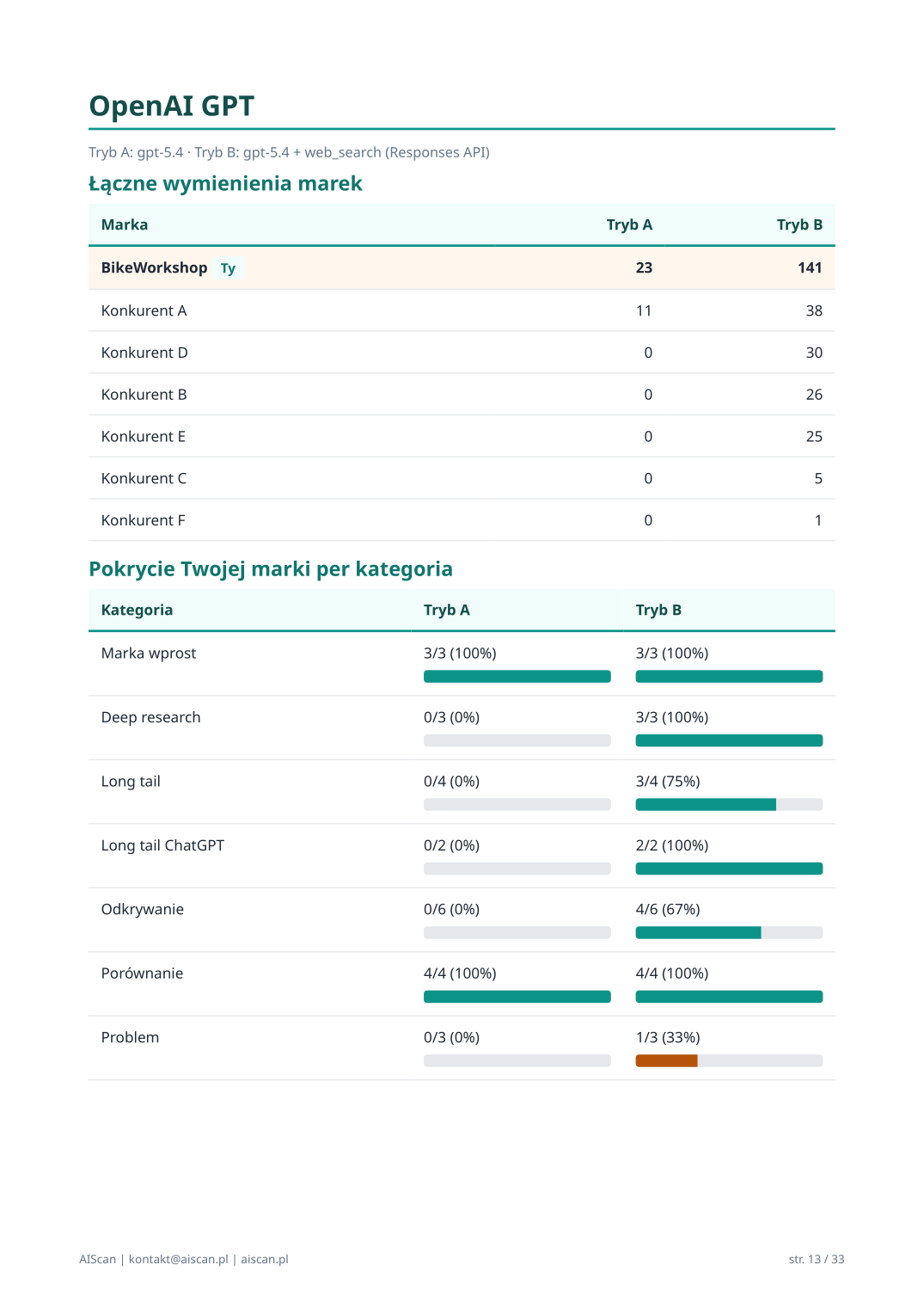
11 · Per provider deep dive — Claude / OpenAI / Gemini osobno
Trzy osobne sekcje (Anthropic Claude, OpenAI GPT, Google Gemini) z identyczną strukturą:
Pokrycie marki klienta — tryb A vs tryb B, per kategoria.
Top 3 wymieniane marki per kategoria u tego konkretnego providera.
Detale per kategoria — pełna analiza dla każdej z 6+ kategorii intencji u tego providera.
Po co osobne sekcje per provider? Bo każdy model AI używa innego źródła wiedzy:
Claude trenowany na Common Crawl + RLHF Anthropic, web_search via Brave
OpenAI GPT trenowany na własnym zestawie + Bing pod spodem dla web search
Gemini trenowany na zasobach Google + native Google Search grounding
Marka niewidoczna u OpenAI Bing-search nie znaczy że jest niewidoczna u Claude Brave-search. Osobne sekcje pozwalają zaplanować strategie różne dla różnych ekosystemów AI.
12 · Metodologia i załączniki
Sekcja transparentności metodologii — pełna lista zadanych promptów (Załącznik A), pełna lista śledzonych marek (Załącznik B), opis trybów A i B, wersje konkretnych modeli użytych w audycie (np. claude-haiku-4-5 w trybie A, claude-sonnet-4-6 + web_search w trybie B), data wykonania audytu.
Disclaimer prawny: raport ma charakter informacyjno-analityczny. Pokazuje stan empiryczny widoczności marki w modelach AI w momencie wykonania audytu. Nie zawiera porad marketingowych, biznesowych ani prawnych. Decyzje pozostają po stronie odbiorcy raportu.
Każdy raport można dowolnie weryfikować — wszystkie odpowiedzi modeli AI są zachowane w surowym JSON (pakiet Standard i Enterprise) i można je odtworzyć w ChatGPT/Claude/Gemini niezależnie.
Pełen raport — podgląd w przeglądarce
Pełen sample.pdf (394 KB, 39 stron A4) — embedded poniżej. Jeśli przeglądarka nie obsługuje wbudowanego PDF, użyj linku „Pobierz".
Słownik pojęć GEO i audytu AI
Zwarty słownik 12 kluczowych pojęć użytych w raporcie i metodologii AIScan. Odzwierciedla aktualny stan terminologii Generative Engine Optimization (2025–2026):
GEO (Generative Engine Optimization)
Optymalizacja treści i obecności marki pod kątem widoczności w odpowiedziach modeli językowych AI (ChatGPT, Claude, Gemini, Perplexity), analogicznie do SEO dla wyszukiwarek (Google, Bing). Kluczowe czynniki GEO: obecność w katalogach branżowych cytowanych przez AI, schema.org JSON-LD, plik llms.txt, treści LLM-friendly (krótkie nagłówki, definicje, listy, tabele).
Share of Voice (SOV) — Organic, Total, Brand recall
Procentowy udział wymienień marki w odpowiedziach modeli AI w trybie B (z wyszukiwaniem webowym). AIScan rozróżnia trzy warianty: Organic SOV (kluczowa metryka raportu) — bez kategorii „Marka wprost" i „Porównanie", w których klient jest podany w pytaniu i pojawia się w odpowiedzi sztucznie; mierzy realną widoczność w spontanicznym discovery klienta końcowego. Total SOV — wszystkie kategorie, zawsze wyższy, podawany jako referencja. Brand recall — udział tylko w „Marka wprost" (gdy AI dostaje nazwę firmy w pytaniu); mierzy jak silnie AI zna markę przy bezpośrednim odpytaniu, niezależnie od organicznego discovery.
Tryb A (bez web search)
Zapytanie do modelu AI bez aktywnego narzędzia wyszukiwania webowego. Model odpowiada wyłącznie z wiedzy zapamiętanej w wagach sieci neuronowej (training data). Reprezentuje długoterminową świadomość marki w „pamięci" modelu — ważne dla brand-direct queries i deep research.
Tryb B (z web search)
Zapytanie do modelu AI z aktywnym narzędziem wyszukiwania webowego. AIScan używa: Anthropic Claude web_search tool z user_location PL, OpenAI web_search via Responses API z user_location PL, Google Gemini googleSearch grounding tool. Reprezentuje user experience użytkownika płatnych planów AI (ChatGPT Plus, Claude.ai Pro, Gemini Advanced), który zawsze ma web search aktywny.
Citation (cytat AI)
URL cytowany przez model AI jako źródło informacji w odpowiedzi. Anthropic Claude udostępnia URL + title + cited_text (literalny fragment ~50–300 znaków). OpenAI GPT przez Responses API zwraca URL z annotation type url_citation (z ?utm_source=openai). Google Gemini zwraca przez vertexaisearch.cloud.google.com redirect z domeną docelową w polu title.
Cited text
Literalny fragment strony cytowany przez Anthropic Claude (jedyny provider zwracający pełny cited_text). Pokazuje konkretny copy strony, który AI uznał za autorytatywną odpowiedź — często fragmenty FAQ, opisy procesów, sekcje cennikowe, opinie klientów cytowane na stronie. Wartościowy do competitive research: jakie treści konkurencji „działają" w AI.
Search query (zapytanie pomocnicze AI)
Zapytanie wygenerowane przez model AI do narzędzia wyszukiwania webowego. Modele AI nie wysyłają literalnego promptu klienta — „tłumaczą" intencję na frazy wyszukiwania, często rozszerzając, dodając synonimy, lokalizację, atrybuty jakościowe. Pokazuje, na jakie konkretne queries warto być widocznym w klasycznym SEO.
Pokrycie kategorii (coverage)
Procent promptów w danej kategorii intencji, w których marka klienta została wymieniona ≥1 raz. Wyświetlane jako frakcja hits/total z procentem (np. 4/6 (67%)). Sześć kategorii intencji: Odkrywanie, Porównanie, Problem, Deep research, Marka wprost, Long tail. Plus opcjonalna asymmetric: Long tail ChatGPT (tylko OpenAI A+B).
Universal blind spot
Kategoria zapytań, w której marka klienta nie pojawia się w 0 z N promptów we wszystkich 3 modelach AI jednocześnie. Najsilniejszy sygnał luki widoczności — dotyczy całej rodziny zapytań intencyjnych, nie pojedynczego providera. Zwykle wymaga reakcji strategicznej (typ treści, schema.org, profile branżowe).
Asymmetria providerów
Sytuacja, w której marka jest widoczna w jednym modelu AI a niewidoczna lub słabo widoczna w innym. Trzy warianty: binarna (≥1 widzi vs 0 nie widzi), skalowa (wszyscy widzą, ale jeden ≥2× rzadziej), per-PCM (konkurent przebijający w konkretnym Provider × Category × Tryb mimo globalnej dominacji klienta). Wskazuje na różnicę w training data lub indeksach wyszukiwania konkretnego providera.
Decision trace (ślad decyzyjny AI)
Pełny rozkład jednej decyzji modelu AI: prompt klienta, search queries, źródła cytowane, kolejność marek, klasyfikacja sygnałów uzasadnienia (11 typów), brakujące dane. AIScan pre-filtruje top 8 najinformatywniejszych traces z 60–80 odpowiedzi audytu (heurystyka: priorytet luk klienta), wzbogaca przez Google Gemini 2.5 Flash-Lite post-processing.
llms.txt
Standard pliku tekstowego (Answer.AI 2024) w katalogu głównym witryny, instruujący modele AI, jak interpretować i opisywać zawartość strony. Format markdown, ~50–150 linii ze streszczeniem strony, faktografią cytowalną, definicjami pojęć, linkami. AI crawlery (GPTBot, ClaudeBot, Google-Extended, PerplexityBot, CCBot, cohere-ai, DuckAssistBot) odczytują go priorytetowo przed indeksacją HTML.
Drugi przykład: kancelaria podatkowa
Aby pokazać horyzontalność produktu, dorzucamy drugi rzeczywisty audyt — kancelaria podatkowa z Warszawy (audyt wykonany 2026-04-26, klient i wszyscy konkurenci anonimizowani — Kancelaria X + Konkurent A–G; liczby wymienień, ranking i fragmenty cytowane są autentyczne, tylko nazwy zastąpione).
Ten sam silnik audytu, ta sama struktura raportu — ale dramatycznie inny obraz klienta vs konkurencji. Kancelaria X ilustruje przeciwny biegun do BikeWorkshop:
Wymiar
BikeWorkshop (sample #1)
Kancelaria X (sample #2, anonim)
Branża
serwis rowerowy (B2C)
kancelaria podatkowa (B2B)
Pozycja w niszy (Organic SOV)
LIDER 35,1% Organic SOV (Total 49,7%)
NIEOBECNY 0% Organic SOV (Total 24,5%)
Brand recall (kategoria „Marka wprost")
100% — AI zna markę gdy podasz nazwę
100% — AI zna markę gdy podasz nazwę, ale nie spontanicznie
Główna luka
OpenAI GPT „Problem" 33% (asymetria providera)
4 kategorie 0% top-of-funnel (Odkrywanie, Problem, Deep research, Long tail)
Authority paradox
bikeworkshop.pl jako #1 cytowana domena (analog konkurent)
kancelaria-x.pl #1 cytowana (72×) — strona = autorytet, ale AI poleca konkurencję
Insight strategiczny
Dominacja ekosystemu AI dla niszy
„Wiedza bez marki" — autorytet domenowy bez brand recall
ChatGPT casual long_tail
ChatGPT odmawia rekomendacji („nie chcę Ci ściemniać")
ChatGPT chętnie poleca imienne nazwiska doradców konkurencji (branża prawnicza ma długą tradycję rankingów)
Te dwa przykłady ilustrują różne narracje sprzedażowe dla różnych pozycji rynkowych: dominant rynkowy potrzebuje monitoringu trajektorii, „zaginiony" potrzebuje diagnozy luk top-of-funnel. Ten sam silnik AIScan dostarcza obu typom mierzalnych danych do decyzji.
Pakiet audytu od 299 zł netto (jednorazowo, promocja na start −14%, cena standardowa 349 zł). Realizacja do 24 godzin od zamówienia, raport PDF + surowe dane JSON. Audyt jest poufny — w przeciwieństwie do tego sample, raporty klientów nie są publikowane.
Sample raport jest rzeczywistym audytem firmy bikeworkshop.pl (serwis rowerowy w Bielsku-Białej, pierwsza linia działalności właściciela AIScan), publikowanym za jego zgodą jako case study. Nazwy konkurentów zostały anonimizowane (Konkurent A–G); ich liczby wymienień, ranking i fragmenty cytowane są autentyczne. Raporty klientów komercyjnych nie są publikowane — są poufne i przechowywane wyłącznie do 30 dni po przekazaniu (zob. regulamin, polityka prywatności).